
אמל”ק
לקחתי קבוצת ווטסאפ של טרמפים והפכתי אותה למפה איך ולמה תקראו למטה
לצפיה במפה –https://udahorn.github.io
בקיבוץ הקטן שלנו יש קבוצת ווטסאפ נהדרת שנקראת “טרמפים-ואהבת לרעך כמוך!”
וכמו שאפשר להבין משם הקבוצה זו קבוצת טרמפים קהילתית. היא מכילה קרוב ל 170 חברים מכל מגוון הגילאים במשק (עם הטיה ברורה כמובן לטובת צעירי המשק על פני הותיקים אבל עדיין טווח הגילאים הוא מגיל העשרה עד גיל הפנסיה).
הקונספט של הקבוצה הוא פשוט אפשר או לבקש טרמפ או להציע טרמפ (טוב כמובן כמו בכל קבוצת ווטסאפ יש גם רעש שאתייחס אליו בהמשך בשלב ניקוי המידע) אם ככה חשבתי יש פה אחלה הזדמנות לציור מפה של בקשות והצעות הטרמפים במשק וליצור ויזולאיזציה לקבוצה , ברגע שהמידע הופך להיות מרחבי אפשר כמובן לנתח לא מעט ניתוחים מרחביים.
בתחילת הדרך של הקבוצה פשוט כל אחד כתב אם הוא מחפש טרמפ או מציע טרמפ, מתישהוא כדי להקל על הקורא נכנסה הצעה לשיפור מי שמציע טרמפ מוסיף אימוג’י של עיגול כחול ומי שמחפש טרמפ עיגול אדום (על המתחכמים למינהם נדבר בהמשך)
על פניו הניתוח המרחבי אמור להיות יחסית פשוט, כל הודעה היא או בקשת טרמפ או הצעת טרמפ וכל הודעה מכילה מוצא או יעד כאשר נקודת המוצא או היעד המשלים הוא משואות יצחק ולכן האפשרויות הם:
- בקשת טרמפ – מהמשק אל X
- בקשת טרמפ מ – X אל המשק
- הצעת טרמפ מהמשק אל X
- הצעת טרמפ מ – X אל המשק
עיבוד המידע
השלב הראשוני הוא כמובן לחלץ את המידע ואת ההתכתבות בקבוצה כדי שיהיה ניתן לעבד אותו, המחשבה להתחבר בלייב לקבוצה ולעבד את הנתונים בלייב ירדה מהפרק וחיפשתי אלטרנטיבה של ניתוח לאחור.
הפתרון מסתבר נורא פשוט, גילתי שיש אפשרות לשלוח את הטקסט של הקבוצה למייל ללא מדיה ולקבל בעצם קובץ טקסט של כל ההתכתבות.
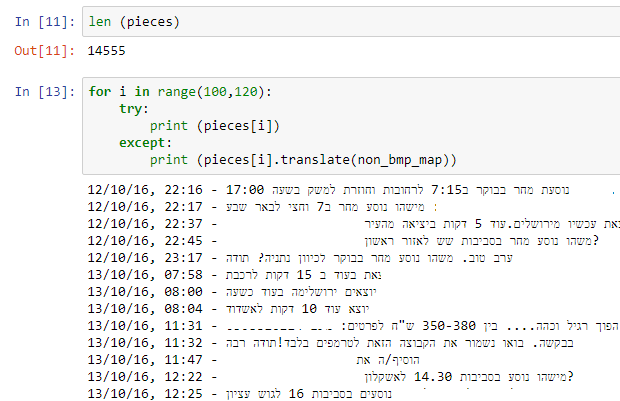
 טוב אז יש לנו קובץ טקסט עם אלפי שורות של התכתבויות (מעל 15 אלף) מה עושים מכאן.
טוב אז יש לנו קובץ טקסט עם אלפי שורות של התכתבויות (מעל 15 אלף) מה עושים מכאן.
את הצעד הראשון התחלתי מסקריפיט בגיטהאב ששימש לי כנקודת פתיחה אח”כ זנחתי אותו כי הוא פחות מתאים לעבודה עם עברית.
הערה הקוד נכתב בשעות הפנאי לאורך תקופה ככה שהוא די מבולגן
הסביבה שעבדתי בה היא jupiter ו python 3
שלב הראשון – קצת אימפורט לספריות שעבדתי איתם. יש 2 ספריות מעניינות אחת bidi שמאפשרת להפוך את הטקסט בעברית זה היה נצרך בשביל להציג גרפים בעברית תקינה והשנייה emoji שמאפשרת עבודה עם האימוג’ים של ווטסאפ
import re
import numpy as np
import pandas as pd
import sys
non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd)
from bidi import algorithm as bidialg
import datetime
from datetime import datetime
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
import emoji
השלב הבא הוא להכניס את קובץ הטקסט לתוך רשימה כך שכל שורה תהיה פריט רשימה
filename = r'...\trempim.txt'
f = open(filename ,encoding="utf8")
file_read = f.read()
r = re.compile('.*/.*/')
pieces = [x.strip('\n') for x in file_read.split('\n') if r.match(x)]
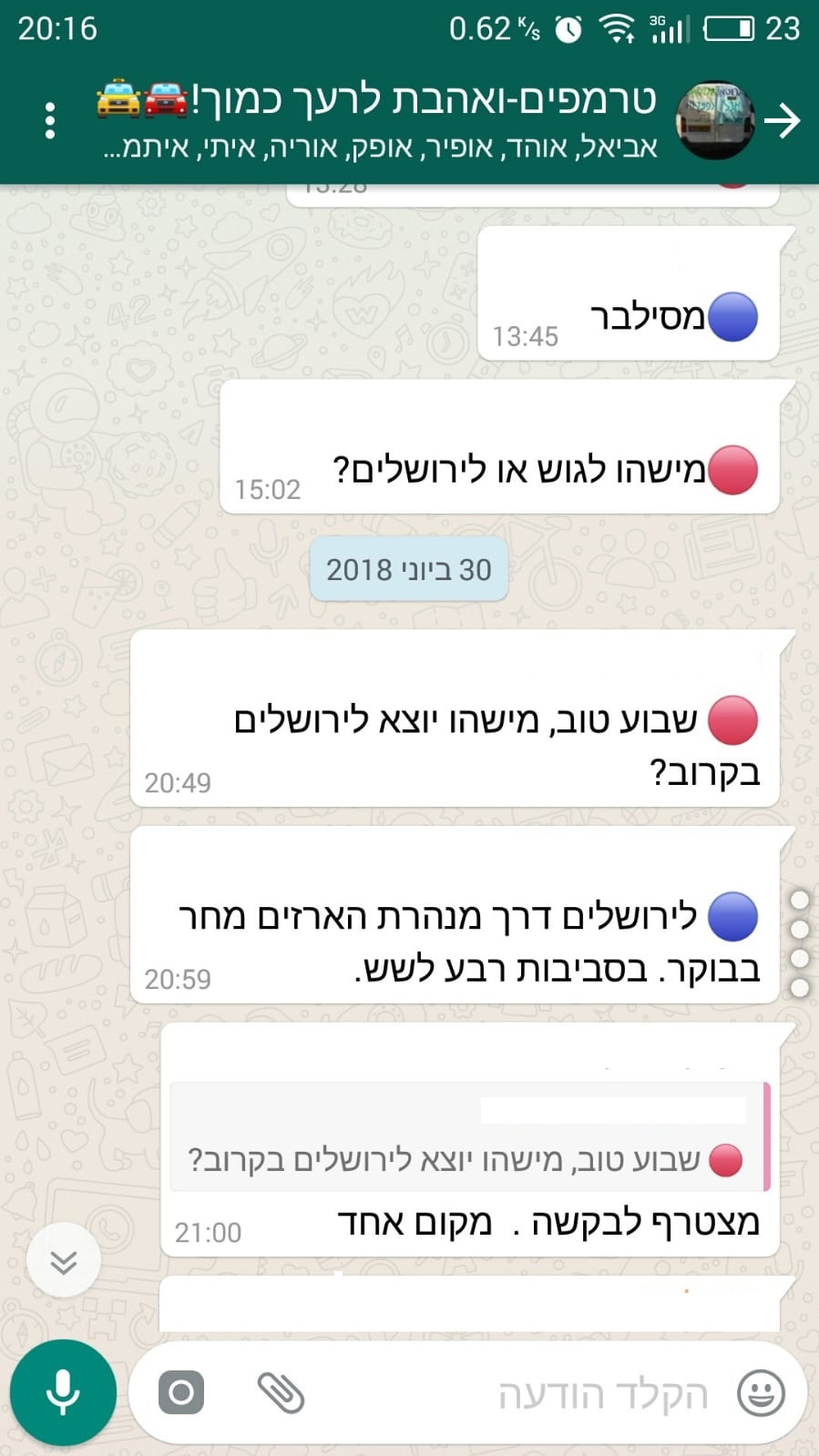
וככה זה נראה כבר בתוך הרשימה, יש פה דוגמה “לליכלוך” שצריך להתמודד איתו וכן לביטויים המרחבים שנתמודד איתם בהמשך (“חוזרת למשק”, “ירושלימה” , “לרכבת”)
הפרינט בקוד מאפשר להדפיס גם אימוג’ים (שבמקרה אין פה בדוגמה).
חילוץ המידע הרלוונטי ובניית בסיס נתונים
השלב הבא הוא כמובן לחלץ את המידע הרלוונטי לתוך טבלה עם עמודות מוגדרות.
לצורך בניית הטבלה השתמשתי ב pandas שלדעתי נותן פיתרון מעולה ומהיר לניתוח נתונים.
העמודות בטבלה הינם : תאריך, משתמש (כלומר מי שלח את ההודעה, עמודה זו לא תוצג במיפוי) , ההודעה , השם בהיפוך (לצורך הצגה בגרפים) , בקשה/הצעה , מהיכן , להיכן, שם היישוב המוצא או היעד שאיננו משואות)
df = pd.DataFrame(columns=['Date', 'User', 'Message',"heb_User","Req/Off","From","To","setl"])
תאריך
החילוץ של התאריך הוא פשוט יחסית שימוש ב split על בסיס הפסיק יחלק לנו את השורה לשתיים והתאריך נמצא בחלק הראשון
pieces[i].split(",")[0]
משתמש
כדי לחלץ את המשתמש אנחנו צריכים לוודא שההודעה היא לא מסוג X הוסיף את Y לקבוצה, ולכן נוציא את השורות שהמילה “את” כלולה בחלק הראשון של ההודעה
if "את" not in pieces[i].split(",")[1].split(" - ")[1].split(":")[0].split(" "):
b=pieces[i].split(",")[1].split(" - ")[1].split(":")[0]
ההודעה
ההודעה עצמה נמצאת בחצי השני של ה split הקודם
pieces[i].split(",")[1].split(" - ")[1].split(":")[1]
שם המשתמש בהפוך
כאמור העמדה הזאת הינה לצורך תצוגת גרפים
d=bidialg.get_display(b)
בקשה/הצעה
כאן אנחנו כבר ממש מגיעים לניתוח של ההודעה ומנסים להבין האם מחפשים טרמפ או מציעים. כזכור בשלב כלשהו בחיי הקבוצה הוחלט כי אימוג’י של עיגול אדום פירושו בקשת טרמפ ואילו עיגול כחול משמעותו הצעת טרמפ. אולם חברי הקבוצה נטלו לעצמם את חירות היצירה ואימוג’ים שונים בגווני כחול ואדום החלו לצוץ כאשר הכוונה היא ברורה לכולם, כחול – מציע , אדום – מבקש.
על מנת להתגבר על הקושי בניתי פונקצייה שדרכה העברתי את ההודעה שכבר חילצנו קודם לכן.
ישנם מילים שחוזרות על עצמם בהצעות טרמפים ומילים שחוזרות על עצמן בבקשות טרמפים אז יצרתי 2 רשימות שמכילות את המלים “החשודות”.
אמרנו אימוג’ים נכון אז בא נראה איך אנחנו מתמודדים עם זה, מסתבר שלכל אימוג’י יש שם שנתן לו אלוהים ונתנו לו אביו ואימו , ובאמצעות ספריית emoji אנחנו יכולים בעצם לקבל את שם האימוג’י (אתר נחמד עם שמות האימוג’ים) ולכן גם יצרתי רשימה של אימוג’ים נפוצים שמשתמשים בהם לסמן בקשה/הצעה , ברור לי שיש כאלו שנפלו בין הכיסאות ולא סימנתי אותם.
וכמובן סימן שאלה בסוף הודעה יסמן לנו בקשה של טרמפ.
בשלב הראשוני נעבור על תווים בהודעה ואם נתקל באימוג’י “חשוד” או בסימן שאלה נדע לשייך את ההודעה, אם לא מצאנו אז נפרק את ההודעה למילים ונחפש את “המילים החשודות”
def OffersRequests(a):
Requests=["מישהו","משהו","מחפשת","מחפש"]
Offers=["יוצא","יוצאת","יוצאים","יוצאות"]
Reqemoji=[ ':red_circle:',':heart:',':feet:',':rose:',':tulip:',':balloon:', ':pushpin:',':high_heel:',':dart:',':strawberry:',':apple:', ':cherries:',':watermelon:',':tomato:']
Offemoji=[':blue_heart:',':blue_circle:',':cyclone:',':small_blue_diamond:',]
check =False
for i in a:
if emoji.demojize(i) in Reqemoji or i =="?":
re="Requests"
check =True
break
elif emoji.demojize(i) in Offemoji :
re="Offers"
check =True
break
if check ==False:
b=a.split(" ")
for i in b:
if i in Requests:
re="Requests"
break
elif i in Offers:
re="Offers"
break
return re
מיקום גיאוגרפי
האתגר שלשמו התכנסנו הוא למצוא את הרכיב המרחבי בהודעה, ולצורך כך צריך להתגבר על מספר קשיים:
- הבנה של כיווניות הנסיעה, האם אנחנו נוסעים אל משואות או יוצאים ממשואות
- בידוד המשתנה המרחבי
- מציאת נקודת המוצא או היעד
- התמודדות עם טעויות כתיב וצורות שונות של שמות מקומות
- קבלת החלטה במקרים של ריבוי יעדים
- “שמות מקומיים” – למשל הרכבת = תחנת רכבת אשקלון, “ביג” = ביג קסטינה וכו’
- מיקום לא מדויק כמו “מישהו נוסע לאיזור..”
- וצרות נוספות של כתיבה בווטסאפ בלי רווחים, סימני פיסוק ועוד
החלטתי שאני מחלק את המידע לשתי עמודות נפרדות ובכל אחת להריץ פונקציה שונה אך דומה אחת תתן את התשובה לשאלה מאיפה נוסעים והשנייה תענה על השאלה לאן נוסעים.
החלטה נוספת הייתה להכין מראש רשימה של יישובים ואפשרויות החלפה בשם היישוב וליצור מילון עם השם הראשי והשמות החלופיים. את הרשימה יצרתי בקובץ XML והכנסתי לתוכה גם את השמות “המקומיים” , עבודה קצת ידנית ושחורה , השתמשתי בתור התחלה באיזה רשימת החלפות ישנה שהייתה לי והרחבתי אותה כולל שימוש במידע על יישובים שנמצא ב https://data.gov.il
החלופה כמובן היא להעביר בגיאוקוד את היעד החשוד , החלטתי לא לבחור בחלופה הזאת מכיוון שגיאוקוד בקוד פתוח מוגבל לכמות בקשות ולי יש כזכור כמעט 15 אלף שורות שכמעט כל אחת צריכה לעבור גיאוקוד.
השימוש ברשימה סגורה הוא כמובן בעייתי בכך שיעד שלא ברשימה לא ימופה , לאחר בדיקות והוספת יעדים שלא היו כלולים ברשימה הגעתי למצב שמעל 9000 רשומות מופו וזה מספיק מבחנתי בשלב זה.
כדי למצוא את המוצא ואת היעד של ההודעה הרצתי בכל עמודה פונקציה נפרדת שמנתחת את הטקסט של ההודעה. בבסיס הפונקציה עומדת הלוגיקה כי כאשר מישהו מציין את המוצא לנסיעה הוא יכתוב “יוצא מ…” והיעד יצויין בהודעה “נוסעים ל..” כך שעל פניו המילה (או מילים) שיופיעו אחרי האותיות מ/ל חשודים כשמות מקומות. ואת המקומות החשודים נכניס לפונקציה נוספת שמבוססת על רשימת היישובים ובמידה ונקבל התאמה הפונקצייה תחזיר את שם היישוב הראשי (ולא השם החלופי שאולי הופיע בהודעה)
יש כמובן לא מעט בעיות בשיטה הזאת כמו יישובים שמתחילים במ’ או ל’ , יישובים עם שני מילים, חיפוש מרובה ייעדים כמו למשל “מישהו נוסע לירושלים/תל אביב” ולכן הפונקציות מלאות ב IF למינהם על מנת לכסות את מרבית האופציות.
התוצאה בסוף היא כזאת אפשר לראות בדוגמה פיספוסים של הסקריפט(דוגמה קטנה מתוך הטבלה המלאה )
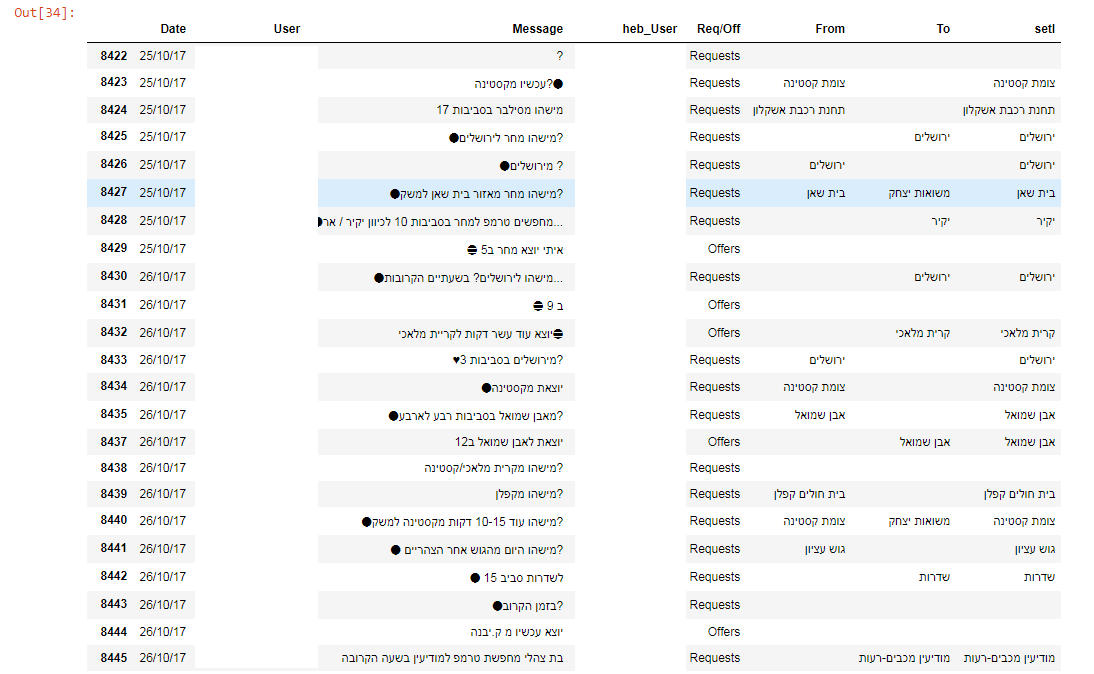
סטטיסטיקות
זה כבר לא קשור ישירות להיבטים מרחביים אבל ברגע שיש לנו טבלה עם כל הנתונים אז אפשר כמובן לחלץ קצת סטטיסטיקות
למשל לראות מי כותב הכי הרבה בכללי וכמובן לפלטר לפי בקשות/הצעות
most_active_user = df.heb_User.value_counts() most_active_user_req=df.loc[df['Req/Off'] == "Requests"].heb_User.value_counts() most_active_user_off=df.loc[df['Req/Off'] == "Offers"].heb_User.value_counts()
מסתבר למשל שאני כתבתי 90 הודעות בקבוצה
most_active_user['Yehuda Horn']
אפשר גם להציג גרפים (ביופיטר) למשל של חמשת המקומות הראשונים של מציעי הטרמפים
most_active_user_off[:5].plot(kind='barh') plt.show()
אפשר כמובן עוד כיד הדמיון הטובה
בניית שכבה גיאוגרפית
זוכרים את רשימת היישובים שלי אז השלב הבא היה להפוך את השמות הראשיים לשכבה עם קורדינאטות והכל , פה כבר עשיתי גיאוקוד דרך QGIS לשכבה בהיטל של WGS84.
את השכבה הזאת (SHP) הפכתי בחזרה ל pandas data fram באמצעות הסקריפט הבא שמצאתי כאן:
def read_shapefile(shp_path): """ Read a shapefile into a Pandas dataframe with a 'coords' column holding the geometry information. This uses the pyshp package """ import shapefile #read file, parse out the records and shapes sf = shapefile.Reader(shp_path) fields = [x[0] for x in sf.fields][1:] records = sf.records() shps = [s.points for s in sf.shapes()] #write into a dataframe df5 = pd.DataFrame(columns=fields, data=records) df5 = df5.assign(coords=shps) return df5
עכשיו מה שנשאר זה בעצם לעשות JOIN בין הטבלאות על בסיס שם היישוב ולהוריד את הטבלה ל geojson על בסיס הקורדינאטות
df6=pd.merge(df, df5, on='setl', how='inner')
def data2geojson(df): features = [] insert_features = lambda X: features.append( geojson.Feature(geometry=geojson.Point((X["lat"], X["lon"])), properties=dict(name=X["setl"],Message=X["Message"],ReqOff=X["Req/Off"],date=X["Date"]))) df.apply(insert_features, axis=1) with open(r"..\map1.geojson", 'w', encoding='utf8') as fp: geojson.dump(geojson.FeatureCollection(features), fp, sort_keys=True, ensure_ascii=False)
data2geojson(df6)
וטדדם יש לנו קובץ מרחבי.
עיצוב ובניית המפה
האמת היא שיותר היה חשוב לי לחלץ את הנתונים מאשר להשקיע בוויזואליזציה של המפה, אבל בכל זאת היו לי כמה תובנות בבנית המפה שאשמח לשתף.
את הקובץ (geojson) שנוצר בתהליך הקודם הכנסתי ל QGIS והתחלתי לעבד אותו , חילקתי לשני קבצים שונים של בקשות והצעות וקצת שיחקתי עם העיצוב , מפות חום וכאלה
השתמשתי בתוסף המצוין qgis2web כדי ליצור מפה ב leflat.
להלן התובנות:
- התוסף עושה עבודה יפה ובונה את דף האינטרנט עם כל הקבצים הנוספים הנדרשים וזה יכול להספיק בחלק מהמקרים אבל כדאי לקרוא קצת את הקוד ולשחק איתו.
- מפות חום לא עולה ב leflat כמו בתצוגה ב QGIS כלומר אין התייחסות לכמות הנקודות ולצפיפות, יש אפשרות להוסיף פרמטר של צפיפות אבל זה לא באמת מציג את הצפיפות. הפתרון העוקף שאני עשיתי היה לכתוב סקריפט קטן בפייתון שמשנה את הקורדינטאות רנדומאלים בפיזור של בערך קילומטר מהנקודה המקורית. אח”כ יש משחקים עם הפרמטרים השונים של מפת החום כדי לקבל תוצאה שניראת לכם מספיקה
var req_1_hm = geoJson2heat(json_req_1,
'');
var layer_req_1 = new L.heatLayer(req_1_hm, {
attribution: '',
radius: 25,
max: 1,
minOpacity: 0.5,
blur: 90,
gradient:{0.4: '#ffb3b3',0.5: '#ff6666', 0.65: 'red', 1:'#661400' }});
- את הפקד של רשימת השכבות יצרתי באמצעות שימוש בסקריפט הזה ולא בצורה הדיפולטיבית שעלתה עם התוסף.
- את הפופאפ בכניסה לדף יצרתי באמצעות הסקריפט הזה
- את הלוגו והלינק יצרתי באמצעות הסקריפט הזה
- התערבתי קצת ב css איפה שהיה נראה לי
- בגדול אפשר למצוא יחסית הרבה מדריכים באינטרנט ובפורומים השונים לפעולות שונות ב leflat אז כדאי לחפש אולי מישהו כבר כתב איזה משהו יעיל
את התוצאה אפשר לראות כאן:
עוד משהו נחמד שמצאתי זה אתר חינמי שאפשר להעלות אליו את קובץ הטקסט של הקבוצה ולקבל סטטיסטיקות שונות
אז למשל הנה ענן המילים של הקבוצה ואפשר להשוות למפה ולראות את זה בא לידי ביטוי..
